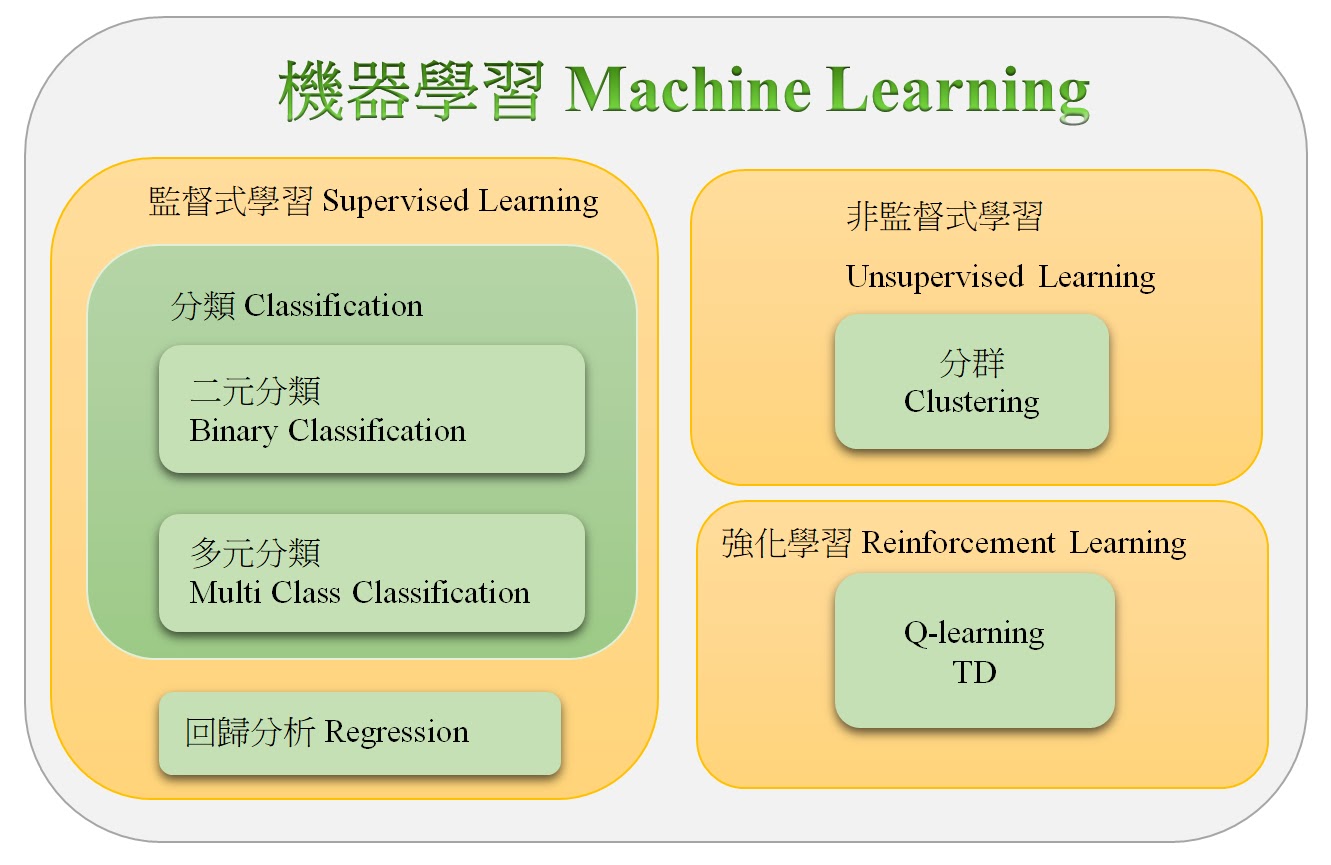
在人工智慧下的機器學習,
其實分有三種類型,
包含「監督式學習」、「非監督式學習」和「增強學習」。
承如人工智慧、機器學習、深度學習介紹,
機器應用相當廣泛,例如:推薦引擎、定向廣告、需求預測、垃圾郵件過濾、醫學診斷、自然語言處理、搜索引擎、詐騙偵測、證券分析、視覺辨識、語音識別、手寫識別等等。
機器學習是人工智慧的分支,機器學習是透過演算法,使用大量資料進行訓練,訓練完成後會產生模型。未來當有新的資料,我們可以使用訓練產生的模型進行預測。
機器學習可分為: 監督式學習(Supervised Learning)、非監督式學習(Unsupervised Learning)、增強式學習(Unsupervised Learning)。
承如機器是怎麼從資料中「學」到東西的呢中提及,
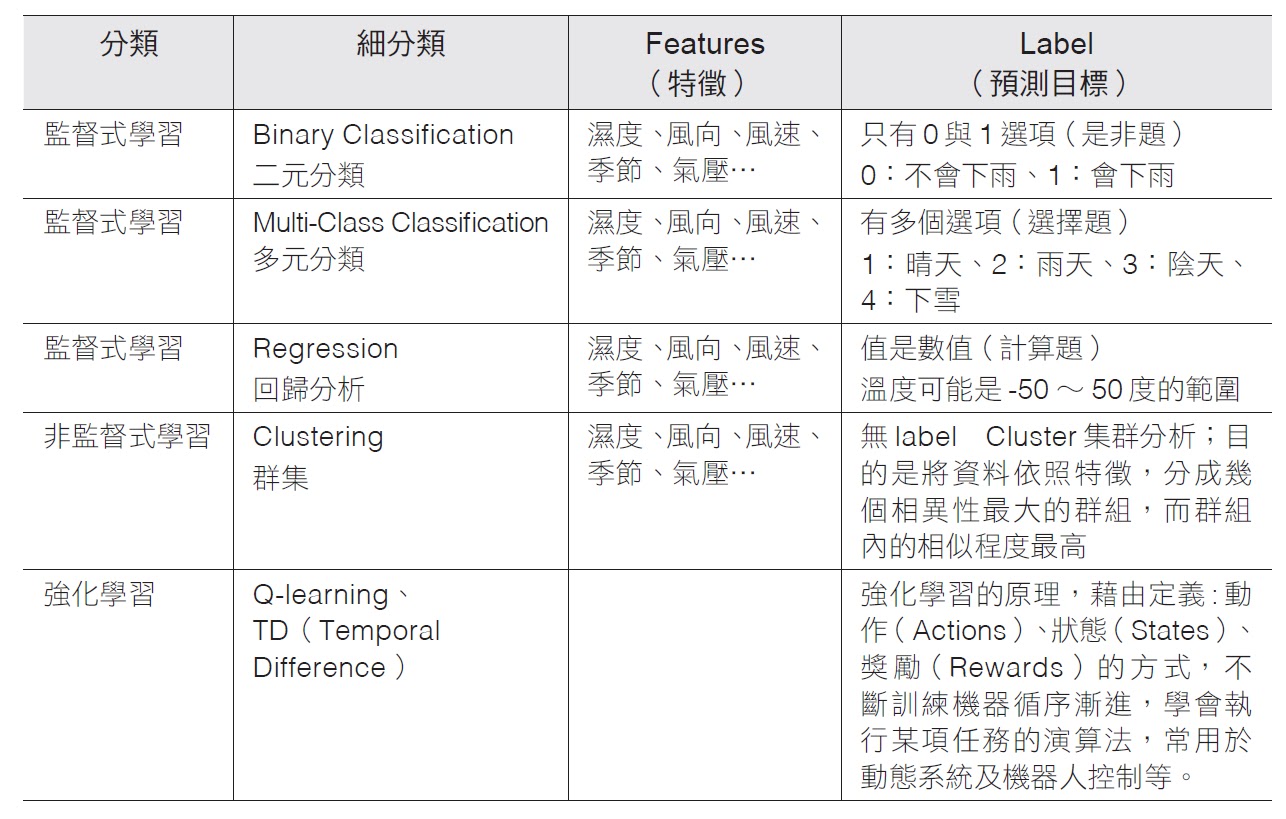
在訓練的過程中告訴機器答案、也就是「有標籤」的資料,
比如給機器各看了 1000 張蘋果和橘子的照片後、詢問機器新的一張照片中是蘋果還是橘子。
訓練資料沒有標準答案、不需要事先以人力輸入標籤,故機器在學習時並不知道其分類結果是否正確。
訓練時僅須對機器提供輸入範例,它會自動從這些範例中找出潛在的規則。
資料沒標籤、讓機器自行摸索出資料規律。
例如集群演算法、關聯規則探索。
透過觀察環境而行動,並會隨時根據新進來的資料逐步修正、以獲得最大利益。
若環境的變化是離目標更接近、我們就會給予一個正向反饋 (Positive Reward),比如當機器投籃時越來越接近籃框;若離目標更遠、則給予負向反饋 (Negative Reward),比如賽車時機器越開越偏離跑道。
我們並沒有給予機器標籤資料,告訴它所採取的哪一步是正確、哪一步是錯誤的,但根據反饋的好壞,機器會自行逐步修正、最終得到正確的結果。
通常「監督式學習」的效果較非監督式學習佳,
因為沒有標籤(Label)來確認,
而只是判斷特徵(Feature)來分群。
除了以上三種機器學習外,
還有學者提出「半監督式學習」,
至於選用哪種方法預測,
取決於資料型態與問題本身。
以上,打完收工。
通常「監督式學習」的效果較非監督式學習佳,
因為**「非監督式學習」**沒有標籤(Label)來確認,
而只是判斷特徵(Feature)來分群。
這句話加個「非監督式學習」指名主詞比較好
因為沒加的話,邏輯上主詞會變成「監督式學習」


 iThome鐵人賽
iThome鐵人賽